阿里面试题
# 1 传统布局和flex布局打区别
# 传统布局
- 盒模型
- 定位布局 position
- 浮动布局 float
- 传统文档流 display 优点:
- 能够做的低版本浏览器的兼容 缺点:
- 代码量大
- 实现一些特殊布局困难,比如垂直剧中,响应式
- 坑点多
- 比较适合做pc端项目
# flex布局
- 弹性盒子 css3的内容,通过控制子盒子来完成布局
- 传统布局实现垂直居中这种特殊布局时相对比较复杂,而flex布局的出现使得实现特殊布局尤其是响应式布局变得更加灵活方便,可以自由设置排列方向,排列顺序,对齐方式,如何换行等
- flex弹性布局,只有四个概念:父容器 子容器 主轴 交叉轴
- 个人原创总结,大家轻拍:传统布局是基于盒模型通过 display,position,float,这些属性的配置来实现网页布局,还原设计稿,如果非得加一个,我还会说说TABLE布局,也算一种。这些布局方式,兼容性好,历史悠久,被广泛用于各种网页排版中,比如双飞燕,圣杯等。但随着电脑的发展,各种终端的涌现,传统布局在前端开发中,出现了很多不方便的地方,老美于2009年,在CSS3标准中,创立了flex布局,故名思意,它是很适合当下的响应式布局发展方向,特别是在对齐,自动适应宽度,布局方向这些地方,通过属性配置,很容易的实现了,传统盒模型所难已达到的的效果,深受前端工程师喜欢,但不过,由于PC终端浏览器产品历史悠久,对CSS3这个新的display:flex的兼容,很不一样,所以在PC端,为了兼容几乎不怎么使用,除非产品定义在高级别浏览器上,在移动端现在的Android4+上,支持的比较好,在注意一些小细节的情况下,比如子元素的display:block这样的问题,大家可以放心使用。总体来说,它的出现是为了适合响应式的WEB前端发展方向而产生,看产品的要求及定位使用而选择使用。
# 2、vue的双向数据绑定的原理是怎么实现的,详细描述什么时候监听变化的,什么时候触发变化的?
Vue双向数据绑定: 我所理解的双向数据绑定无非就是在单向数据绑定的基础上给可输入元素,比如input和textarea添加监听事件来动态修改model和view,其最核心的方法就是通过Object.defineProperty()来实现对对属性的劫持,达到监听数据变化的目的。 要实现mvvm双向数据版绑定, 我觉得需要实现以下几点: 1.实现一个数据监听器Observer,能够对数据对象的所有属性进行监听,如有变动可以拿到最新值并通知订阅者。 2.实现一个指令解析器Compiler,对每个元素节点的指令扫描并解析,根据指令模板替换数据,并且绑定相应的更新函数。 3.实现一个watcher,其作为连接Observer和Compiler的桥梁,能够订阅并收到每个属性变动的通知,执行指令绑定的回调函数从而更新视图 4.MVVM作为入口函数,整个以上三者
5af8eb55f265da0b814ba766 视频 https://pan.baidu.com/s/1Zi7axziluvmdP7XLd7-jWg 密码:31b3
# 3、比较两个颜色的相似度
这是一道开放题目,首先将颜色拆分成r/g/b三个值,如果是字符串的颜色如#aabbff或者rgb(255,128,100)可以用正则表达式取出对应的r/g/b值。对于16进制字符串,可以使用parseInt('0xaa')转10进制整数。然后对于两个颜色,可以使用距离 Math.sqrt( (r1-r2) (r1-r2) +(g1-g2)(g1-g2)+(b1-b2)*(b1-b2) )进行比较, 距离近则相似。 当然可以用Math.hypot( r1-r2, g1-t2, b1-b2) 来简化上述运算。 这道题目主要考察学员的知识积累和思考。 首先要知道rgb是颜色的组成。 然后要给出一种可行的比较方法。 最后要考察具体javascript细节函数的运用
- 阿里
- 颜色基本组成
- RGB 正方体 计算器 离散 解析
- 000 - 111 对角线 亮度 垂直面 锥形 圆环
- 加权求距离 人对绿色更敏感 权重高
- 人工智能 神经 计算 权重
- 错误 转换十六进制 相减
- RGB 平方做差 加权平均值
- 饱和度 亮点
- 计算机视觉 面试 人对颜色低理解 不同人种对颜色低认真差异不同
# 4 业务题
问题:一个单页面应用,有6张页面,F、E、A、B、C、D。 页面ABCD构成了一个冗长的用户验证过程。目前A、B、C对应用户验证过程的第1步,第2步,第3步。 页面F是首页,E是某张业务相关页面。用户到达页面E后,系统发现用户没有认证,触发验证流程,到达页面A,然后开始A->B->C->D流程。 页面D是验证结果页面(验证成功页面)。 请问,如果到达页面D后,如何让用户点击返回可以返回页面F,而忽略中间流程(注:用户可能根本没有到达过F,比如微信分享直接进入了E)。 补充下: 场景是上述场景,最好能做到到达页面D后,浏览器自然返回是F,再按返回,单页面系统退出;另外请思考下各个流程如何实现流畅切换,不会有中间闪烁的页面。
答案: 这个问题初一看是对单页面路由架构的考察。也是一个很好的引入问题,可以考察非常多方面。 比如说:如何实现页面切换动画? A、B、C都是表单的话,如何缓存用户输入完成的表单数据?……回到问题,因为history api提供了push/pop/replace三种操作,无论是其中的任何一种都无法实现上述的效果。 一个路由系统,首先要监听浏览器地址的变化,然后根据变化渲染不同的页面。1. 在页面到达D后,关闭对路由变化页面渲染的监听。 2. 路由系统要进行多次POP,可以用history.go(-n)实现; 3. 路由栈清空到只剩下一张页面时,将这张页面替换为F。 4. PUSH一张页面D。 5. 如果在HTML上有一个类似「轮播图」的设计,就是每一张页面是一张轮播图,将轮播图设置成只有「F」和「D」。 5. 恢复路由监听。 这个问题的另一个考点是,在上述完整的计算过程当中,需要知道当前历史记录中的页面数,页面数可以通过localStorage实现,在ls中维护一个变量,每次push的时候+1,并写入history.state。 POP的时候读取history.state将变量重置。
- 单页面路由
- 单页面,div部分改变 -- 路由改变就是replace浏览记录会被replace掉
- push可以返回
- go()
# 5 算法题
问题 一个无序正负项 数组, eg:[3, -6, 123, -945, -231, 112] 找出其中的最大的连续子序列
有如下乱序数组 A1, A2, A3, A4,........An, 求 i, j (1<= i <= j<= n), 使得Ai + .... + Aj 和最大, 输出i j
# 6 请你说说函数防抖和函数节流的应用场景和原理?
防抖 应用场景,比如一个输入框 输入文字请求数据 输入的时候每变化一次就请求一次 这就需要用防抖了 节流 比如下拉加载更多请求接口,这就需要用到节流了,每隔多少秒去执行一次 防抖的实现原理是 比如300毫秒的间隔时间,如果没有到300毫秒又输入内容那么重新计算着300 秒时间 等什么时候停止输入 再去请求数据, 节流是 比如下拉加载数据 同样时间是300毫秒 触发 就是第一次请求数据 隔300 毫秒再去请求数据
函数节流(throttle):限制一定时间内只能执行一次 应用场景:下拉刷新,屏幕滚动 设置一个变量,判断函数是否可以执行,false时直接退出,设置间隔时间
function throttle(fn, interval = 300) {
let canRun = true;
return function () {
if (!canRun) return;
canRun = false;
setTimeout(() => {
fn.apply(this, arguments);
canRun = true;
}, interval);
};
}
2
3
4
5
6
7
8
9
10
11
函数防抖(debounce):连续,当两次函数触发大于一定时间时真正触发函数
function debounce(fn, interval = 300) {
let timeout = null;
return function () {
clearTimeout(timeout);
timeout = setTimeout(() => {
fn.apply(this, arguments);
}, interval);
};
}
2
3
4
5
6
7
8
9
# 7 场景面试
电商网站A和电影票网站B合作,A的用户,可以通过A网站下单购买电影票,之后跳转跳转到B(不需要登录)去选座位。 如果A、B是同域名,比如a.domain.com,b.domain.com能不能共享cookie?如果不同域如何处理?
# 8 请说说什么是XSS?如何攻击?如何防御?
内容安全策略 (CSP) 是一个额外的安全层,用于检测并削弱某些特定类型的攻击,包括跨站脚本 (XSS) 和数据注入攻击等。无论是数据盗取、网站内容污染还是散发恶意软件,这些攻击都是主要的手段。
我们可以通过 CSP 来尽量减少 XSS 攻击。CSP 本质上也是建立白名单,规定了浏览器只能够执行特定来源的代码。
通常可以通过 HTTP Header 中的 Content-Security-Policy 来开启 CSP
只允许加载本站资源
只允许加载 HTTPS 协议图片
允许加载任何来源框架
Content-Security-Policy:default-src 'self' Content-Security-Policy:img-src 'https://' Content-Security-Policy:child-src 'none'
https://content-security-policy.com/
https://eggjs.org/zh-cn/core/security.html
# 9 说说csrf,什么是csrf,怎么防范它?
如何防御 防范 CSRF 可以遵循以下几种规则: Get 请求不对数据进行修改 不让第三方网站访问到用户 Cookie 阻止第三方网站请求接口 请求时附带验证信息,比如验证码或者 token #SameSite 可以对 Cookie 设置 SameSite 属性。该属性设置 Cookie 不随着跨域请求发送,该属性可以很大程度减少 CSRF 的攻击,但是该属性目前并不是所有浏览器都兼容。 #验证 Referer 对于需要防范 CSRF 的请求,我们可以通过验证 Referer 来判断该请求是否为第三方网站发起的。 #Token 服务器下发一个随机 Token(算法不能复杂),每次发起请求时将 Token 携带上,服务器验证 Token 是否有效。
# 10 如果发现在某个用户的电脑上,网站的静态资源打不开了,如何确定是CDN的问题还是那个用户机器、浏览器的问题?
# 11 请说说在hybrid端实现类似原生般流畅的体验,要注意哪些事项。
# 12 https抓包的原理是什么?平时你用什么工具?如何抓包?
# 13 什么是无头浏览器
# 14 请说一下V8下的垃圾回收机制
# 15 请说一下对执行上下文的理解
当执行 JS 代码时,会产生三种执行上下文 全局执行上下文 函数执行上下文 eval 执行上下文
# 16 请说说你对Event loop的理解?浏览器中的Event loop和Node中的Event loop的异同?
# 17 0.1 + 0.2 != 0.3?
# 18 Service workers
Service workers 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API。 目前该技术通常用来做缓存文件,提高首屏速度,可以试着来实现这个功能。
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register("sw.js")
.then(function(registration) {
console.log("service worker 注册成功");
})
.catch(function(err) {
console.log("servcie worker 注册失败");
});
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener("install", e => {
e.waitUntil(
caches.open("my-cache").then(function(cache) {
return cache.addAll(["./index.html", "./index.js"]);
})
);
});
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener("fetch", e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response;
}
console.log("fetch source");
})
);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 18 你在项目中如何进行 Webpack 优化?
- 缩小文件搜索范围,配置比如resolve.modules,resolve.modules,resolve.mainFields,resolve.alias ,resolve.extensions ,module.noParse 配置
- 使用DllPlugin 要给 Web 项目构建接入动态链接库
- HappyPack 就能让 Webpack 做到这点,它把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程
- 当 Webpack 有多个 JavaScript 文件需要输出和压缩时,原本会使用 UglifyJS 去一个个挨着压缩再输出, 但是 ParallelUglifyPlugin 则会开启多个子进程,把对多个文件的压缩工作分配给多个子进程去完成
- 可以监听文件的变化,当文件发生变化后可以自动刷新浏览器,从而提高开发效率。
- (Hot Module Replacement)的技术可在不刷新整个网页的情况下做到超灵敏的实时预览。 原理是当一个源码发生变化时,只重新编译发生变化的模块,再用新输出的模块替换掉浏览器中对应的老模块。
- Tree Shaking 可以用来剔除 JavaScript 中用不上的死代码。它依赖静态的 ES6 模块化语法,例如通过 import 和 export 导入导出
- 可以使用CommonsChunkPlugin 把多个页面公共的代码抽离成单独的文件进行加载
- Webpack 内置了强大的分割代码的功能去实现按需加载,可以用import实现路由按需加载。
- Scope Hoisting 可以让 Webpack 打包出来的代码文件更小、运行的更快, 它又译作 "作用域提升"
- 可以使用可视化分析工具 Webpack Analyse等去分析输出结果,从页进行优化.
- 对于 Webpack4,打包项目使用 production 模式,这样会自动开启代码压缩
- 优化图片,对于小图可以使用 base64 的方式写入文件中
- 给打包出来的文件名添加哈希,实现浏览器缓存文件
# 829 请说一下ES6中 Generator 的实现原理?
# 830 什么是IFC?IFC的作用?
# 831 什么是跨越?常用的跨越方式有哪些?
# 903 请说说cookie,localStorage,sessionStorage,indexDB之间的区别的使用场景?
# 参考答案


# 参考文献
# 904 写一个函数find_missing(A, low, high),给定一个范围[low,high],寻找一个数组中缺失的元素。
find_missing([10, 12, 11, 15], 10, 15) // [13,14]
// 注: low=10 high = 15
find_missing([1, 14, 11, 51, 15],50, 55) // [50, 52, 53, 54]
// 注:low = 50, hight = 55
2
3
4
5
6
# 答案
本题考查对算法复杂度的理解,简单两次循环或者filter/map等等嵌套循环,可以在O( (high -low) * A.length )复杂度完成,但是通过排序可以优化到O(nlgn)+O(high - low)。
function find_missing(A, low, high){
const B = A.filter(x => x >= low && x < high).sort((x,y) => x - y)
let j = 0
return [...Array(high - low )]
.map((_, i) => i+low)
.filter(x => B[j] !== x ? true : !!!++j)
}
2
3
4
5
6
7
# 905 讲讲输入完网址按下回车,到看到网页这个过程中发生了什么?
# 答案
# 参考资料
# 906 谈谈你对前端资源下载性能优化的经验和思考?
# 907 IP协议属于哪一层?主要功能是干什么的?
# 参考答案:
IP协议对应于OSI标准模型的网络层。 IP协议的主要功能-用途:在相互连接的网络之间传递IP数据报。其中包括两个部分:
(1)寻址与路由。 (a)用IP地址来标识Internet的主机:在每个IP数据报中,都会携带源IP地址和目标IP地址来标识该IP数据报的源和目的主机。IP数据报在传输过程中,每个中间节点(IP 网关)还需要为其选择从源主机到目的主机的合适的转发路径(即路由)。IP协议可以根据路由选择协议提供的路由信息对IP数据报进行转发,直至抵达目的主机。 (b)IP地址和MAC地址的匹配,ARP协议。数据链路层使用MAC地址来发送数据帧,因此在实际发送IP报文时,还需要进行IP地址和MAC地址的匹配,由TCP/IP协议簇中的ARP(地址解析协议)完成。
(2) 分段与重组。 (a) IP数据报通过不同类型的通信网络发送,IP数据报的大小会受到这些网络所规定的最大传输单元(MTU)的限制。 (b)将IP数据报拆分成一个个能够适合下层技术传输的小数据报,被分段后的IP数据报可以独立地在网络中进行转发,在到达目的主机后被重组,恢复成原来的IP数据报。
# 参考资料:
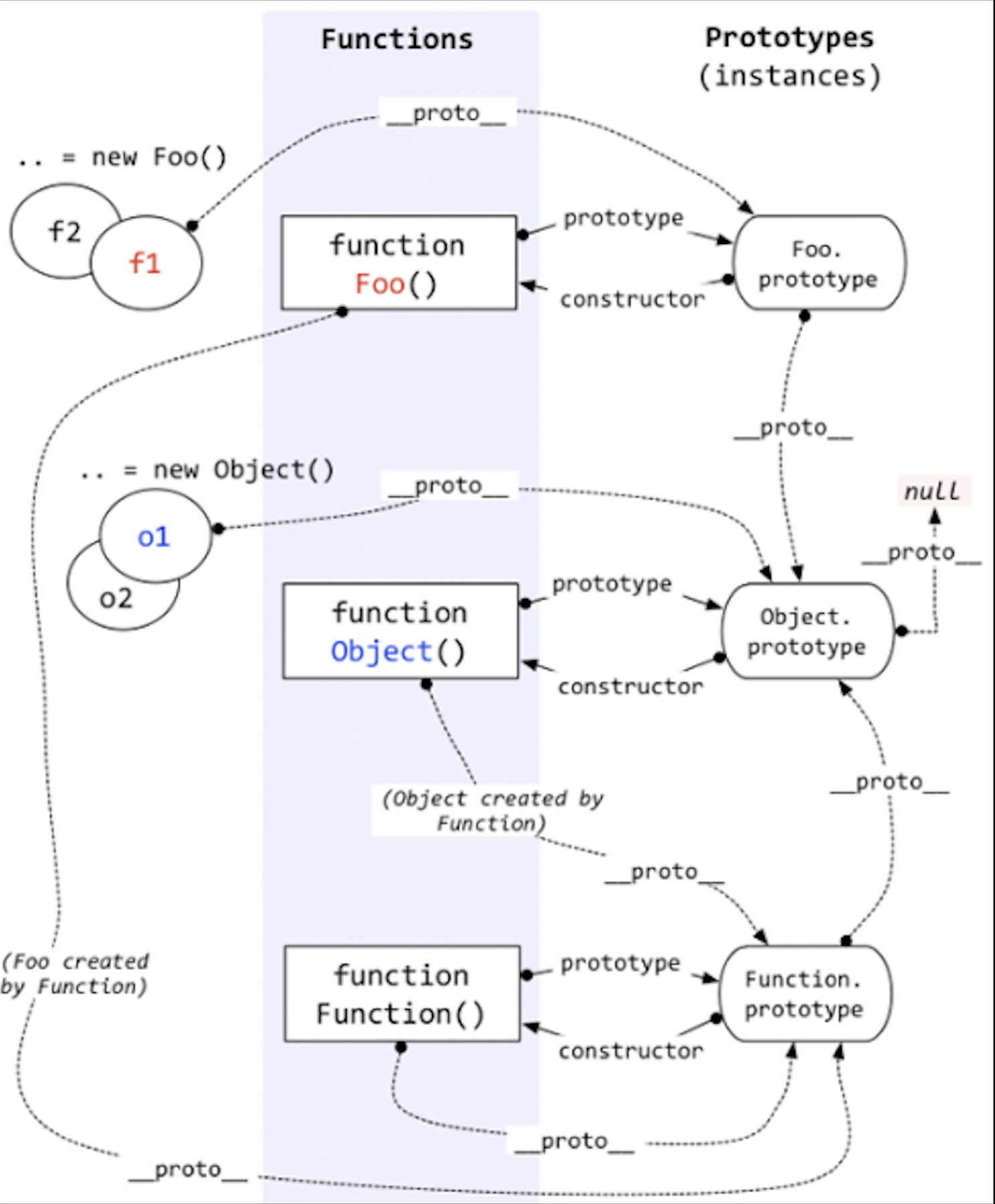
# 910 js 中的 new()到底做了些什么?
# 参考答案:
new 运算符创建一个用户定义的对象类型的实例或具有构造函数的内置对象的实例。
当代码 new Foo(...)执行时,会发生以下事情:
一个继承自 Foo.prototype 的新对象被创建。
使用指定的参数调用构造函数 Foo,并将 this 绑定到新创建的对象。new Foo 等同于 new Foo(),也就是没有指定参数列表,Foo 不带任何参数调用的情况。
由构造函数返回的对象就是 new 表达式的结果。如果构造函数没有显式返回一个对象,则使用步骤 1 创建的对象。(一般情况下,构造函数不返回值,但是用户可以选择主动返回对象,来覆盖正常的对象创建步骤)
var cat = new Animal("cat");
new Animal("cat") = {
var obj = {};
obj.__proto__ = Animal.prototype;
var result = Animal.call(obj,"cat");
return typeof result === 'object'? result : obj;
}
2
3
4
5
6
7
- 创建一个空对象 obj;
- 把 obj 的
__proto__指向 Animal 的原型对象 prototype,此时便建立了 obj 对象的原型链:obj->Animal.prototype->Object.prototype->null - 在 obj 对象的执行环境调用 Animal 函数并传递参数“cat”。 相当于
var result = obj.Animal("cat")。当这句执行完之后,obj 便产生了属性name 并赋值为"cat"。【关于 JS 中 call 的用法请阅读:JS 的 call 和 apply】 - 考察第 3 步返回的返回值,如果无返回值或者返回一个非对象值,则将 obj 返回作为新对象;否则会将返回值作为新对象返回。
# 参考资料:
# 911 下面是一个bind方法的Polyfill,请逐句给别人讲解一下每一行代码的含义
Function.prototype.bind = function(oThis) {
if (typeof this !== 'function') {
throw new TypeError('Function.prototype.bind - what is trying to be bound is not callable');
}
var aArgs = Array.prototype.slice.call(arguments, 1),
fToBind = this,
fNOP = function() {},
fBound = function() {
return fToBind.apply(this instanceof fNOP
? this
: oThis,
aArgs.concat(Array.prototype.slice.call(arguments)));
};
if (this.prototype) {
fNOP.prototype = this.prototype;
}
fBound.prototype = new fNOP();
return fBound;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 参考答案:
# 参考资料:
# 912 你的移动端适配怎么做的?
# 媒体查询
其实媒体查询方式除了类似bootstrap之类的基础类库 很少在真实项目中使用
# 百分比+px
百分比+px方式对于适配开发者来说最容易 但是自适应性比较差 demo小项目用下还可以 我自己在小项目也会使用
# rem(比较主流)
- rem方式是目前比较主流的 知名的方案有淘宝的flexible 基本原理是将页面宽度分成10份 但是这时候页面的rem大小已经没法口算了 需要接入postcss之类的构建工具才能够使用 待vw单位兼容性渐渐不那么严重了 就可以使用vw替代flexible vw是将页面分成100份 基本思路是一致的
- 另外一种rem布局思路是在默认设计稿尺寸的时候设置根元素font 为100px或者50px 好处是rem值可以根据设计稿标注口算 但是不会兼容vw了 看怎么取舍
- 那么rem vw 就没有问题吗?不是的! rem 还是 vw 在使用额时候都会出现小数点 小数点会造成精度缺失 在雪碧图或者其他极端精确像素的场景 总会出现裁剪错误 同时rem不适合用在文字大小上 文字大小用px会更合适
# vw
- 拓展阅读: vw布局
# 参考资料
- https://www.w3cplus.com/css/vw-for-layout.html 张巍耀老师总结的一些文章:
- 移动端屏幕像素的那些事 (opens new window)
- 再说viewport (opens new window)
- 移动端下的1px (opens new window)
- 移动端REM方案-Flexible源码分析 (opens new window) 张巍耀老师基于flexible的rem解决方案(在上一个部门支撑了基本所有的SPA和多页面网页,对PC端、iPad、Android缩放等问题都进行了特殊处理):rem-moka (opens new window) 本来rem-moka我也写了一篇源码解析文章,只不过还没来记得发,大家有兴趣可以看看源码
# 913 请说一下在JS中this的完整取值规则?
this跟函数在哪里定义没有关系,函数在哪里调用才决定了this到底引用的是啥
this机制的四种规则
- 默认绑定全局变量,这条规则是最常见的,也是默认的。当函数被单独定义和调用的时候,应用的规则就是绑定全局变量。
- 隐式绑定 隐式调用的意思是,函数调用时拥有一个上下文对象,就好像这个函数是属于该对象的一样
- 显示绑定 学过bind()\apply()\call()函数的都应该知道,它接收的第一个参数即是上下文对象并将其赋给this。
- new新对象绑定 如果是一个构造函数,那么用new来调用,那么绑定的将是新创建的对象
# 914 请说一下谈谈JS中的垃圾回收机制?
- V8 实现了准确式 GC,GC 算法采用了分代式垃圾回收机制。因此,V8 将内存(堆)分为新生代和老生代两部分。 #新生代算法 新生代中的对象一般存活时间较短,使用 Scavenge GC 算法。 在新生代空间中,内存空间分为两部分,分别为 From 空间和 To 空间。在这两个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满时,新生代 GC 就会启动了。算法会检查 From 空间中存活的对象并复制到 To 空间中,如果有失活的对象就会销毁。当复制完成后将 From 空间和 To 空间互换,这样 GC 就结束了。
- 老生代算法 老生代中的对象一般存活时间较长且数量也多,使用了两个算法,分别是标记清除算法和标记压缩算法。 在讲算法前,先来说下什么情况下对象会出现在老生代空间中: 新生代中的对象是否已经经历过一次 Scavenge 算法,如果经历过的话,会将对象从新生代空间移到老生代空间中。 To 空间的对象占比大小超过 25 %。在这种情况下,为了不影响到内存分配,会将对象从新生代空间移到老生代空间中。
- 在老生代中,以下情况会先启动标记清除算法: 某一个空间没有分块的时候 空间中被对象超过一定限制 空间不能保证新生代中的对象移动到老生代中 在这个阶段中,会遍历堆中所有的对象,然后标记活的对象,在标记完成后,销毁所有没有被标记的对象。在标记大型对内存时,可能需要几百毫秒才能完成一次标记。这就会导致一些性能上的问题。为了解决这个问题,2011 年,V8 从 stop-the-world 标记切换到增量标志。在增量标记期间,GC 将标记工作分解为更小的模块,可以让 JS 应用逻辑在模块间隙执行一会,从而不至于让应用出现停顿情况。但在 2018 年,GC 技术又有了一个重大突破,这项技术名为并发标记。该技术可以让 GC 扫描和标记对象时,同时允许 JS 运行。 清除对象后会造成堆内存出现碎片的情况,当碎片超过一定限制后会启动压缩算法。在压缩过程中,将活的对象像一端移动,直到所有对象都移动完成然后清理掉不需要的内存。
# 917 什么是深拷贝和浅拷贝?如何实现深拷贝?
# 918 原型是什么?原型链是什么?用你的语言把下面这张图讲解清楚